
预训练语言模型
- ELMO(2018.2): word representation。加上双向LSTM作为模型,在语料上做预训练
- 预训练方式:因为是双向LSTM,所以能计算前向概率以及后向概率,两者相乘就得到了第n个单词生成的概率(算是常规的操作了,和CRF之类的基本差不多)。作者是对logP进行优化,所以就相当于进行相加。最终的优化目标还是句子的生成概率。该生成概率和GPT之类的生成模型的生成概率不一致。为每个单词的条件生成概率相乘,条件为其他所有单词。 \(\begin{equation} p\left(t_{1}, t_{2}, \ldots, t_{N}\right)=\prod_{k=1}^{N} p\left(t_{k} \mid t_{1}, t_{2}, \ldots, t_{N}\right) \end{equation}\)
- 然后将输入以及模型所有层的输出拼接在一起,作为下游任务的输入。
- 同时论文还给不同层的输出设置了权重,该权重通过在下游任务中训练得到(作者在论文中提到,底层的输出对语法更为关注,而顶层的输出则对语义信息更为关注。)。
-
GPT(2018.1):生成式,自回归,最大化最大似然函数。关键在预训练。Transformer decoder
-
GPT2(2019): 仅仅是更大。关键在多任务zero-shot
-
GPT3(2020.5): 更大杯,few-shot learning变得很好。
- BERT(2018.10):
- 预训练目标: Token mask + Next sentence prediction
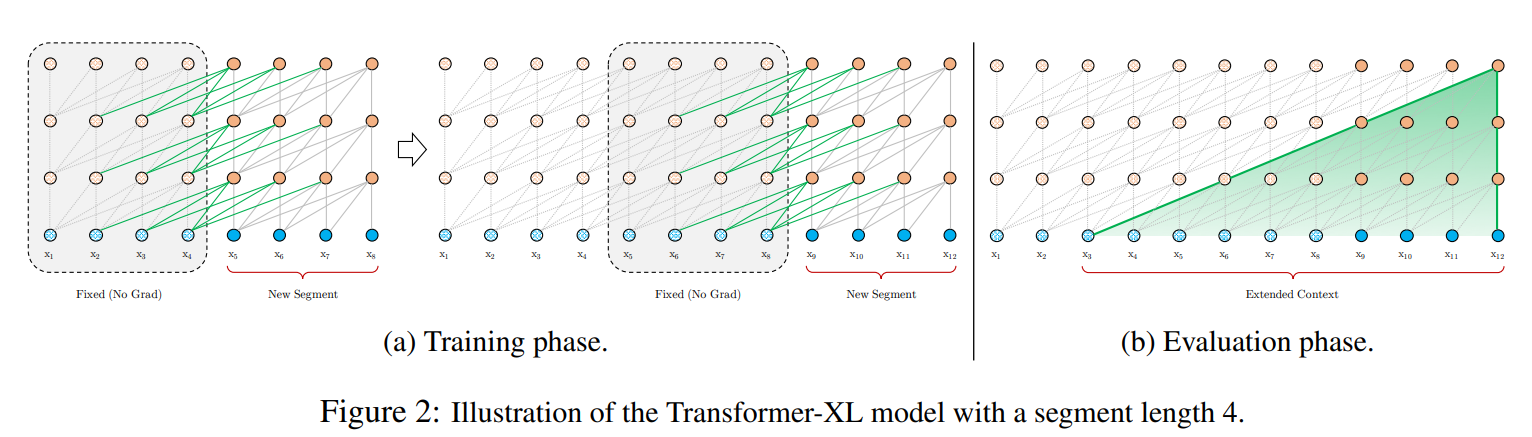
- Transformer-XL(2019.01):为了学长距离依赖关系。采用了 relative sinusoidal positional embeddings。同时使用了上一个片段的embedding,但不回传梯度。
- 除了原始的transformer当前片段的输入,同时引用上一片段的输入,但是不回传梯度。
- XLNet(2019.01): 是在Transformer-XL上做的,也是自回归。作者认为引入MASK标签,会使训练和预测不一致。
- 作者没有使用Mask,而是引入了自回归的模式,使得一部分词语不可见。但是通过shuffle token得index,使得不可见的词语并不是按原始文本顺序,而是按shuffle后的顺序。使得能学会双向注意力机制。
- 上述机制主要是在Attention上加mask做具体实现(基本上和其他模型实现使一致的,并不是真的训练时搞自回归预测)
- 上面提到的方式解码时候不知道解码顺序,于是引入位置参数作为输入,引导输出对应的结果。作者引出了其特殊的注意力机制以及增加了部分参数。
- 该模型难以收敛,作者提出仅仅预测末尾几个单词,同时不预测得单词,就不计算其\(g\)参数,减少计算量。
- 也去掉了NSP。
- 不同句子拼接时候,仅标识attention里两个token是否来自同一个片段。
- RoBERTa(2019.7):It builds on BERT and modifies key hyperparameters, removing the next-sentence pretraining objective and training with much larger mini-batches and learning rates.
- 同时处理了模型输入。NSP任务中会拼接不同文章的文本,并且如果只拼接短句子,会使得无法学会远距离依赖。
- 直接去掉NSP效果不错。
- 梯度累计来做大batch。
- 换了BPE编码器,以byte做单位而不是unicode。
- ALBERT(2019.9): 降低参数数量,但是不减少计算量
- 降低参数量的方法:
- Splitting the embedding matrix into two smaller matrices.
V*H -> V*E + E*H
作者认为WordPiece Embedding是用来学上下文无关的信息的。而 hidden-layer embeddings 是为了学上下文相关信息的,所以两者维度无需一致。 - Using repeating layers split among groups. * 增加了loss:
- We also use a self-supervised loss that focuses on modeling inter-sentence coherence, and show it consistently helps downstream tasks with multi-sentence inputs
作者认为该任务难度更高 * others: - 使用了n-gram masking
- 使用了absolute position embedding
-
T5(2019.10):探索迁移学习的极限。we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts all text-based language problems into a text-to-text format
-
ELECTRA(2019.10):用小的generator替换token后,用discriminator判断是否有被替换。作者声称这样做数据利用率更高,而不是仅仅几个mask掉的token会被用到。
generator梯度不来自discriminator而是最大似然函数。
对BERT唯一的修改是和ALBERT一样,embedding 分解 - BART(2019.10):降噪自编码器
- 预训练方式:
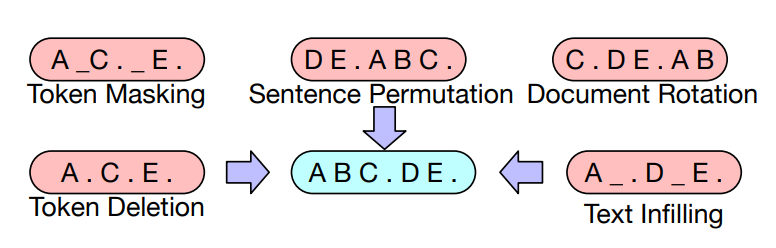
虽然有些地方会加mask,但是不一定有东西被mask掉。
- 预训练方式:
-
Reformer(2020.1):模型改进,局部敏感哈希替代attention
- Pegasus(题外话):是挑和剩下文本覆盖度高的句子作为摘要。
reference: huggingface和各自的论文
Written on April 5, 2022