
工作前的论文以及代码阅读
强化学习
- Top-𝐾 Off-Policy Correction for a REINFORCE Recommender System:
- Difference between on-policy and off-policy:
- Reinforcement Learning: An Introduction
- Value-based and policy-based
- log-trick in REINFORCE gradient calculation[1]:To solve such optimization problems, we have to take the derivative of the expectation, which is not as easy as in the case where we optimize empirical loss instead of the true expected loss because we do not know the true data distribution. In the previous case, the parameter we want to optimize does not depend on the sample. However, in the latter, the dependency of the loss and the parameter is only through the samples, once we sample, the loss doesn’t depend on the parameter anymore. Therefore, we can’t just use empirical estimation and get around. Here we have to really deal with the expectation.(看不懂) 不能使用重参数化技巧吗?什么鬼东西,我看完强化学习那本书之后,我觉得log-trick只是为了将期望公式变成可训练的相加形式,将其展开并且变得更加简单了。
- 公式三: 这个就是off-policy的一个经典策略吧,没什么好说的,将概率值更正了,展开就是了。哦,主要是为什么要用到未来的t,主要是因为R的计算中用到了未来的reward吧,我觉得是,但是是不是这样的,需要自行推公式的。
- sampled softmax
- temperature in softmax(✔)
- why we should reduce gradient variance?[2, 3]:为了使训练更加稳定,防止梯度过大或过小
- 为了继续减少gradient variance 将correction 连乘的项数减少了,虽然是有偏的,但是作者觉得无所谓了。但是呢,你这里并没法定义用户
- weight capping:好像是非负的吧
- Boltzmann exploration
- actor-critic[3]:参考链接里的内容没看完
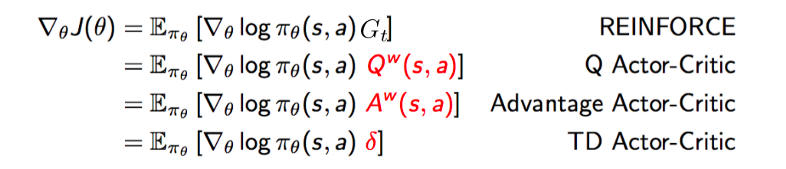
- q-learning[4]
- reinforce:
- behavior policy $\beta$ ,item embedding可以训练,但是,user state那里梯度不回传的话,user state一直变化,但是item embedding是不变化的?????:只学一个$\theta$,这个可以当作item embedding,但是不会用的。
- gumbel(softmax采样)[5]:复杂度可以降低到O(n).
- 离散变量采样[6]:有O(1)的欸,直接就是生成一个array,其中数值分布按概率分布来,然后随机选一个就好了。
- 这里肯定没有看完的,但是我也不知道看到哪里了。。。。
- 还有一个是behaviour policy的获得,为了获得behavior policy,直接使用了原始生成的所有推荐物品,所以即便有多个agent来生成推荐的序列也能尽量去模拟。而且因为生成的是behavior policy并不需要对点击率什么的进行预估,所以把所有的item都是都丢进去训练,而action policy使用有reward的点击进行训练呢, 即便将所有的东西丢进去,因为reward是零,所以其实也并不更新的。
- Difference between on-policy and off-policy:
-
Deep Reinforcement Learning: Pong from Pixels[7]:这个是直接对概率进行更新,使采样的概率更偏向于正向的。但是没有reward估计的部分。
- REINFORCE:第一次看到
itertools.count(),还挺好玩的,可以用这个写while True.
word2vec
code reading [8]
- word采用有一个很有意思的东西,就是,如何快速采样呢?解决方案就是生成一个非常大的表里面按照概率放词汇然后就能$O(1)$对word进行采样了。连续的区间也能这样处理!!!
- haffman树和负采样是一个能相互替代的关系!!原始代码中,两者不同时使用。
- 里面随机数生成竟然是自己生成的,就是初始一个数,然后反复乘以一个非常大的数字,再取最低16位后取值,重新反复乘得到新的数字。
- 梯度是自己手动算的呀,难怪论文这么强调梯度这个东西。
- 还有激活函数是预先算好丢到表里,然后通过int访问
- TODO: 但是呢,
- TODO:我是不懂skip-gram实现上的问题。
- TODO:没仔细看如何更新参数的。
参考文献
Written on November 9, 2022