
LDA
LDA [1]
文本集合的概率模型,文本-话题,话题-单词矩阵的多项式概率参数由狄利克雷分布生成,但是仅生成一次,并不是没生成一个单词就生成一个分布,所以可以计算。和逻辑回归的参数可以假设符合正态分布类似,同时该假设与l2正则等价。参数符合预设的分布能降低过拟合概率。
-
定义:
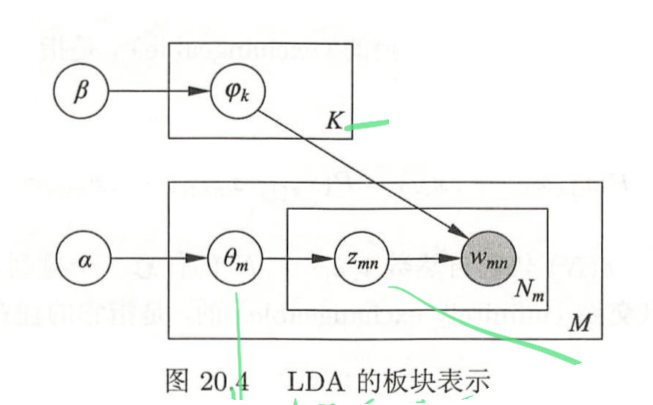
-
概率计算:LDA假设文本由无限可交换的话题序列组成。
\[\begin{equation} p(\mathbf{w}, \mathbf{z}, \theta, \varphi \mid \alpha, \beta)=\prod_{k=1}^{K} p\left(\varphi_{k} \mid \beta\right) \prod_{m=1}^{M} p\left(\theta_{m} \mid \alpha\right) \prod_{n=1}^{N_{m}} p\left(z_{m n} \mid \theta_{m}\right) p\left(w_{m n} \mid z_{m n}, \varphi\right) \end{equation}\] -
学习算法:
- 狄利克雷分布有一些重要性质: (1)狄利克雷分布属于指数分布族; (2)狄利克雷分布是多项分布的共轭先验(conjugate prior)。
- 狄利克雷分布的后验分布的参数等于先验分布参数加上统计计数。(既然有观察到一定的数据,说明就不是先验分布的概率分布了,其概率分布是与观察到的数据相关的)
- 吉布斯抽样算法:(从吉布斯抽样到具体算法,how????)
- 使用转移核$p(x, x’)=q(x,x’)\alpha(x,x’)$的马尔科夫链是可逆马尔科夫链。
- $q(x, x’)$ 一般使用容易抽样的分布。
- 如何保证其平稳分布是目标分布?
- 需要满足: \(\begin{equation} \pi(y)=\int p(x, y) \pi(x) \mathrm{d} x, \quad \forall y \in \mathcal{S} \end{equation}\)
- 书上有证明,还算简单
- 作者使用collapsed Gibbs sampling,对后验概率分布$p(\mathbf{w}, \mathbf{z} \mid \alpha, \beta)$进行抽样,再对其他参数进行估计。如何进行估计看书里的进行推导。(z是话题,所以后面抽的就是话题)
- 具体的话就是
- 根据平均的多项分布随机为每个词分配话题,然后分别增加话题-词语,话题-文本的统计数据。直到所有词语分配话题完成。
- 然后根据统计数据,计算隐变量,重新概率,然后重新分配话题,直到燃烧期结束。
- 变分EM算法:这个完全不懂了。
- 通过定义一个简单的概率分布,使用KL divergence使该分布尽量接近原始分布,最终解得该替代的概率分布,得到近似的参数。
- 狄利克雷分布有一些重要性质: (1)狄利克雷分布属于指数分布族; (2)狄利克雷分布是多项分布的共轭先验(conjugate prior)。
参考文献
-
统计学习方法(第二版) ↩
Written on April 25, 2022